Dentro de la amplia gama de problemas que la visión computacional busca resolver, el problema de reconocimiento facial no requiere de mucha introducción. Es fácil entender su gran impacto en aplicaciones de negocios, seguridad, legales, etc. Probablemente todos los que lean este articulo se habrán encontrado con alguna aplicación móvil que la requiera. Y hasta puede que se hayan preguntado por que su aplicación no es aún más masiva.
En este articulo me gustaría presentar mi trabajo en una variante particular del problema de reconocimiento facial: el reconocimiento de rostros a partir de videos. Explicado en sencillo, el desafío es lograr reconocer a la mayor cantidad de personas que aparecen en un video a medida que avanza. Es decir, si al segundo 23 apareció Juan Perez y al segundo 43 Maria Sandoval, queremos que el sistema reconozca a cada uno de ellos durante todo el tiempo que permanezcan en escena. Al final de la escena queremos tener una secuencia de recortes del rostro de Juan y otra secuencia de recortes del rostro de María. Si más adelante en el video, Juan o María vuelven a aparecer, queremos re-conocerlos y saber que son ellos. Aunque tengan otra ropa o estén en otro lugar físico.

El sueño
Tal como yo lo definiría, el sueño de un sistema de reconocimiento de rostros a partir de videos es el siguiente: Imaginemos que ponemos una cámara en pleno Paseo Ahumada, y que grabamos los rostros de todos los que pasan por ahí. Detectamos a cada persona que transita, obtenemos la representación de su rostro en un vector de espacio latente y lo guardamos en una base de datos de gran tamaño (20 millones de chilenos). Esto significa que guardaremos decenas de millones de secuencias. Cada secuencia contendrá el rostro de una persona a medida que se mueve en la escena. Días después y en otro extremo de la ciudad (un Mall concurrido, una estación de Metro, etc) el sistema realiza la misma operación. Luego de procesar la nueva secuencia, una notificación automática registra en la base de datos que la misma persona fue vista en ese nuevo lugar. Vale la pena aclarar, que tal como está definido este sistema, no estamos buscando identificar a las personas (asignar nombre, rut, domicilio a cada rostro, etc), sino re-conocer que hemos vuelvo ver al mismo rostros en otra parte del video (e.g rostro 2345 visto en lugar X y luego en lugar Y con fecha y hora respectiva).

Estado del arte
Al leer la bibliografía técnica acerca de reconocimiento facial, es usual encontrar un conjunto de términos técnicos que pueden llevar a confusión si no son definidos correctamente. A continuación daremos una definición sucinta de cada uno.
- Detección de rostros (face detection): Problema en que se busca obtener todas las regiones dentro de una imagen, que contienen rostros. La salida es típicamente una lista de coordenadas (bounding boxes) para cada rostro. Ver definición de paperswithcode.com/task/object-detection. La métrica de evaluación más usada es Mean Average Precision (mAP).
- Clasificación de rostros (face classification): Problema en que se busca asignar una clase (class or label) a un rostro. Las clases forman un conjunto finito, numerable y conocido a priori. Ver definición de paperswithcode.com/task/image-classification. La métrica de evaluación más usada es seleccionar un punto de operación desde la curva ROC del clasificador.
- Identificación de rostros (face identification): Lo mismo que clasificación de rostros. Ver definición de paperswithcode.com/task/face-identification. A veces es llamada face matching en inglés.
- Agrupamiento (clustering): Es el problema de agrupar un conjunto de datos no-clasificados en subconjuntos disjuntos (realizar una una partición). Cada elemento del conjunto original es asignado a una clase. El número de clases no es conocida a priori. Ver definición de paperswithcode.com/task/clustering. A diferencia de los demás problemas, el agrupamiento no tiene una métrica de evaluación estándar. Es decir, no es fácil comparar dos algoritmos y determinar cual lo ha hecho mejor. Ya que en principio, todas las particiones son igualmente buenas. Es aquí donde se abren dos alternativas. La primera es introducir una partición de referencia para evaluar que tan cerca o lejos estamos de ella. Esto convierte inmediatamente a este problema en uno de clasificación, ya que ahora conocemos el número de clases y su distribución. A lo sumo podríamos decir que este problema es equivalente a un clasificador en que el número de clases varia con el tiempo (aumenta al aprender un nuevo rostros y disminuye si decidimos olvidarlo). La segunda alternativa surge cuando no existe o no conocemos la partición de referencia. Existe una serie de indices para medir cuan compactos son los elementos de una misma clase y cuan alejadas están las clases entre si: Davies–Bouldin index, Dunn index, Silhouette coefficient entre otros. Sin embargo, estos indices no son una métrica de evaluación, pues en el fondo, el problema de agrupamiento es blando y no exacto. El problema de agrupamiento es más parecido al de redondeo de números que a una clasificación estricta (redondear hacia arriba, hacia abajo, o truncar depende del contexto). De hecho existen nuevos algoritmos de agrupamiento de tipo probabilístico (probabilistic clustering ) o con traslape (overlapping clustering).
- Reconocimiento de rostros (face recognition): Es el problema de detección y clasificación de rostros. Ver definición de paperswithcode.com/task/face-recognition.
Existe muchísima bibliografía de reconocimiento facial. Sin embargo, acá nos estamos enfocando en reconocimiento en base a videos, es decir, reconocimiento que haga uso de la variable temporal. Las implementaciones frame-a-frame no son consideradas, porque presuponen de una estructura y contexto que no se da en el escenario que nos planteamos. Es decir, videos de vigilancia de áreas públicas, y no uno de fotos tomadas con el expreso deseo de ser bien tomadas (luz, pose, nitidez, etc). Es por ello que soluciones como Amazon Rekognition, daon.com, idemia.com y similares no son consideradas acá.
El análisis de la bibliografía del área representa un desafío en si misma. Ya que esta bastante repartida en trabajos que buscan distintos objetivos. Esto es tan así, que me ha llevado a creer que una de las principales razones para el gran avance de los modelos de redes neuronales, ha sido la existencia de desafíos claros y dataset accesibles. Esto ha permitido crear tableros de seguimiento unificados y verificables como los de Face Recognition en paperswithcode.com. Da la impresión que esta cultura de problema unificado + datos abiertos + métricas de seguimiento ha sido clave en el éxito del área. Por ejemplo, el reconocimiento de rostros en base a imágenes tiene tableros como el siguiente.
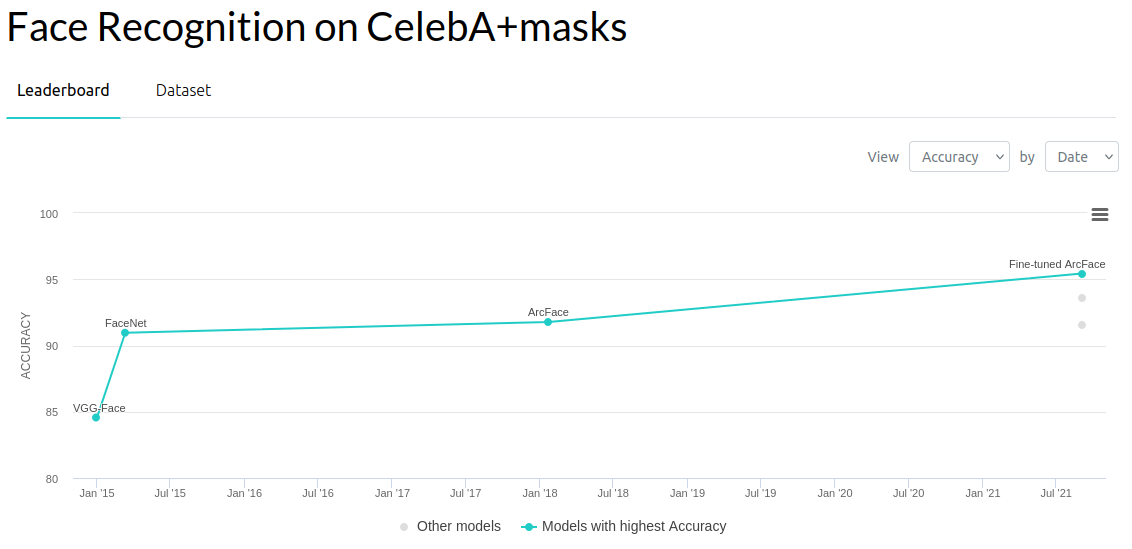
En el caso de reconocimiento facial a partir de videos, si bien existen dataset disponibles (YouTube Faces DB, IJB-S, HACS), la definición de que problema se quiere resolver aún no tiene una delimitación unificada. Algunos autores asumen conocer el número de rostros, otros asumen conocer la distribución de vectores latentes a priori, otros son métodos online, otros son offline. Es decir, cada uno arma su problema de manera distinta al anterior.
Desde un punto de vista más técnico, lo que diferencia el reconocimiento en base a videos es el incorporar la variable temporal dentro del análisis, y decidir en base a una secuencia de imágenes de rostros (no una sola), si un rostro es conocido o es nuevo. En la literatura existen al menos dos estrategias para resolver el problema: (1) agrupar las detecciones de rostros y comparar entre agrupaciones, y (2) fusionar las detecciones de rostros en una sola representación (un solo vector) y comprar entre esas representaciones. Para el primer caso se suelen ocupar técnicas de búsqueda y comparación de vectores en clusters. Para el segundo caso existen algoritmos que fusionan las secuencias en un solo vector, como por ejemplo, averaging, temporal pooling o los famosos attention mechanisms de los LLM. A pesar de las dificultades ya advertidas, algunos de los trabajos más relevantes del 2006 a la fecha son:
- EVERINGHAM, Mark; SIVIC, Josef; ZISSERMAN, Andrew. Hello! My name is… Buffy’’–Automatic Naming of Characters in TV Video. En BMVC. 2006. p. 6.
- Este trabajo es en gran medida el que despertó el interés por el problema de identificar rostros en un video. En este caso los autores utilizaban análisis de rostros y subtítulos para nombrar a cada personaje en la escena. Esto no es el problema principal que estamos buscando resolver, pero pertenece a la mismo tronco general de identificación en base a videos.
- WU, Baoyuan, et al. Constrained clustering and its application to face clustering in videos. En Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2013. p. 3507-3514.
- En este trabajo, los autores buscan generar tracklets (secuencia temporal de detecciones de un mismo rostros), para entrenar un modelo de agrupamiento (clustering model) basado en cadenas ocultas de Markov (Hidden Markov Random Fields). Ellos asumen conocer el número de rostros (personas) en el dataset, y en base a ese número, las detecciones de rostros (vector latente y bounding box) se usan para ajustar un modelo, basado en Markov, que las asigne a sus respectivas rostros (clusters). La variable aleatoria oculta es la imagen de cada rostro, y la variable observable es el vector latente (el embedding de esa rostro). La matriz de transición de la cadena de Markov es modelada como una función que fuerza el enlace entre rostros de un mismo tracklet (aumenta la probabilidad de transición), y a su vez, fuerza el no-enlace de rostros de tracklets temporalmente paralelos (dos rostros en una escena). Dos problemas parecen surgir con este método. El primero y más cuestionable es que la variable oculta no es aleatoria, pues cada rostro entra y sale de escena de manera determinista en cada video. No es aleatoria entre frame y frame, y esta altamente correlaciona con los instantes previos y futuros. Esto viola los supuestos de un proceso de Markov. El segundo problema es que requiere de un ajuste paramétrico (optimización), el cual se hizo usando el mismo dataset con que se evaluó.
- JIN, SouYoung, et al. End-to-end face detection and cast grouping in movies using erdos-renyi clustering. En Proceedings of the IEEE International Conference on Computer Vision. 2017. p. 5276-5285.
- Este es uno de los primeros trabajos que he encontrado en que se busca pasar desde video a clusters de rostros. Separan su trabajo en dos partes, la primera es la generación de tracklets (secuencia temporal de detecciones de un mismo rostros). En la segunda parte realizan el agrupamiento usando un corolario de teoría de grafos llamado Erdos-Renyi y la métrica rank-1 count para generar los clusters y verificarlos respectivamente. La hipótesis del trabajo es encontrar un valor de corte (threshold) para la métrica de rank-1 count que entregue un muy baja tasa de Falsos Positivos, de manera que prediga con alta precisión (pero baja exhaustividad) que rostros son los mismos. El corolario de Erdos-Renyi asegura que los poco puntos de intersección en común entre secuencias de un mismo rostro pero de distinto tracklets generarán, con muy alta probabilidad, un grafo cerrado para cada rostro. Generarán, por tanto, un agrupamiento (cluster) distinto y definido para cada rostro. Para aceptar que dos tracklets son de un mismo rostro, ocupan la métrica en un subconjunto de 10 vectores de cada uno, y toman el máximo valor del rank-1 count. Si ese valor sigue siendo menor al valor de corte, entonces se acepta fundirlos en un solo agrupamiento (cluster). El potencial problema de este trabajo (para nuestro objetivo) es que asumen conocer la distribución de la métrica de los pares de rostros. Además, ocupan una partición de entrenamiento (train) para calcular el valor de corte que les de una baja tasa de FP. La otra partición es ocupada para pruebas (test), y así medir la efectividad del algoritmo.
- YANG, Jiaolong, et al. Neural aggregation network for video face recognition. En Proceedings of the IEEE conference on computer vision and pattern recognition. 2017. p. 4362-4371.
- Este trabajo es altamente novedoso ya que realizan una reducción N a 1 de las imágenes de rostros de un tracklet. Las cuales son convertidas a espacio latente y luego combinadas en un único vector latente. Esta última etapa se realiza por medio de dos bloques de atención que agregan (combinan) todos los vectores latentes de entrada en uno solo. Este vector de salida está dentro de la envolvente convexa (convex hull) de los vectores de entrada. Esto, ya que el vector de salida es, literalmente, la combinación lineal de las entradas. Lo importante es que el peso para el i-esimo vector no es estático, sino que es una función de ese mismo vector de entrada. Es justamente este generador de pesos (llamado kernel) el que requiere de entrenamiento. El generador de pesos actúa como un filtro que reduce la importancia de vectores correspondientes a imágenes pequeñas o mala calidad, y prioriza los vectores de imágenes de buen tamaño y calidad. La tarea de comparación de tracklets y rostros es más fácil de realizar pues quedan ambos limitados a un solo vector respectivamente.
- KULSHRESHTHA, Prakhar; GUHA, Tanaya. An online algorithm for constrained face clustering in videos. En 2018 25th IEEE International Conference on Image Processing (ICIP). IEEE, 2018. p. 2670-2674.
- Este trabajo busca crear un algoritmo online para agrupar rostros. La distinción entre métodos offline (donde conocemos las rostros de antemano, aún que sea un subconjunto de test) y online es crítica, pues significa no conocer distribuciones de probabilidad, ni el número de rostros (clusters) a priori. Los autores proponen que las rostros detectadas en cada segmento de video, sean asignadas a un cluster existente o a uno nuevo. Es decir, que se re-conozca al rostro, o se declare como nuevo. Esto lo hacen generando tracklets de rostros en el video. Los tracklets se extienden cuando el traslape temporal (frame anterior y frame actual) es superior al 85% y cuando la distancia entre esos dos vectores latentes es menor a 0.1 (unidad arbitraria que depende del modelo generador del espacio latente). Ellos definen una medida de distancia entre el baricentros de una de las rostros conocidas y todos los vectores de un tracklet determinado. Por medio de un umbral (threshold) deciden si asignar al tracklet a una rostro conocida (actualizando el baricentro) o crear una rostro y baricentro nuevo. A través de matrices se añaden las restricciones de tracklets correspondientes a rostros que aparecen en paralelo en una misma escena y que se asumen como siempre distintas. Ellos evaluaron su método con dos datasets: Buffy - the Vampire Slayer (BF2006) y The Notting Hill (NH2016).
- TAPASWI, Makarand; LAW, Marc T.; FIDLER, Sanja. Video face clustering with unknown number of clusters. En Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019. p. 5027-5036.
- Este articulo se propuso agrupar (cluster) todos los rostros observados en videos (6 episodio de la primera temporada de The Big Bang Theory y 6 episodio de la temporada 5 de Buffy - La caza vampiros) de manera que coincidieron con el número de personajes. Esto lo hicieron sin conocer a priori el número de personajes (rostros distintos) en cada episodio.
- GUNTHER, Manuel, et al. Toward open-set face recognition. En Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. 2017. p. 71-80.
Códigos disponibles
En cuanto a las implementaciones disponibles. Algunos repositorios que tienen algún nivel de reconocimiento en video son:
- https://github.com/wansook0316/MultiFaceTrackerUsingDeepsort
- https://github.com/deepinsight/insightface
- https://github.com/ankuPRK/COFC
- https://github.com/deepinsight/insightface
Airflow: Mi (humilde) implementación
¿Como implementar el sueño?
En este proyecto se trabajó con las siguientes herramientas tecnológicas:
Videos
Un conjunto de videos que muestre a personas y sus rostros. En este proyecto simplemente saqué un video de Youtube sobre la inauguración de Metro. Como primera etapa haremos re-conocimiento dentro del mismo video. Pero luego queremos extender esto a un conjunto de miles de videos.
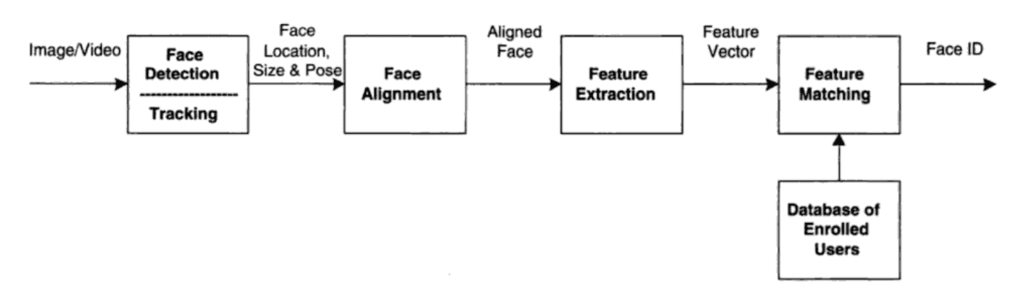
Detector de rostros
Acá no hay mucho misterio. Los detectores tienen una larga historia dentro de la visión computacional. Son el segundo caso más usado luego del clasificador de imágenes. En este proyecto se usó el modelo insightface para detectar rostros de personas.
Estimador de pose
Para esta parte también usamos insightface ya que además de ser un modelo detector, entrega por cada rostro un vector que representa si la persona está mirando de frente, de costado, arriba abajo. Este estimador es muy importante para procesar solo los recortes de rostros en que la persona está mirando de frente y por tanto podrá ser reconocida de buena manera.
Descriptor de rostros
Este problema es muy antiguo dentro del área de reconocimiento de rostros. Antes del uso masivo de redes neuronales se usaban detectores de keypoints (ojos, nariz, boca, orejas, mejillas, etc) para elaborar matemáticamente un vector descriptor. Un buen resumen de estos algoritmos se puede ver en Gururaj Et al. 2024 Comprehensive. Algunos de estos métodos clásicos son: HOG, Eigenface, Independent Component analysis, Scale-Invariant Feature Transform (SIFT), Gabor filter, Local Phase Quantization (LPQ), Linear Discriminant Analysis (LDA), entre otros.
Sin embargo, todo esto fue reemplazado por el uso de redes neuronales de aprendizaje profundo que generan vectores descriptores de mucho mayor calidad. Diversos métodos de entrenamiento han sido propuestos para mejorar el desempeño de estas redes. Los dos más conocidas son aquellos derivados de la función softmax de clasificación y el de triple-loss.
En este proyecto usamos el modelo insightface que además de ser un modelo detector de rostros, entrega por cada rostro un vector descriptor. Este vectors descriptor es el que usaremos para comprar rostros. En particular el modelo que usamos fue entrenado usando una función de perdida llamada ArcFace que ha tenido muy buen desempeño.
Base de datos
En este proyecto se uso Postgres. Esta es una base da datos de alto desempeño y muy usada. Se interactúa con ella a través de SQL. Y en ella se almacena la información de cada rostros detectado, y su relación con el frame del video en que fue obtenido.
Existe un complemento de Postgres llamado pgvector que es clave para transformar a una base de datos clásica en una base de datos para IA. Existe toda una industria centrada en interactuar con datos no estructurados que basan su funcionamiento en bases de datos de vectores. Estos vectores son una especia de «tarjeta de presentación» de los datos no estructurados (pdf, imágenes, audio, etc).
Comparación de vectores
Esta es un área de investigación muy activa y compleja, ya que el uso de vectores descriptores es la base sobre la que se sostienen muchas aplicaciones: búsqueda de imágenes, sugerencias de compra, minería de datos, etc. Además de esto, la industria de vectores descriptores está siendo usada para dar algo de orden (buscar, relacionas, entender) la gigante masa de datos no estructurados.
En el caso del reconocimiento de rostros. La forma más sencilla (pero no la más robusta) de reconocer rostros es comparar el vector latente del desconocido, contra los vectores de rostros de la base de datos. Hacer una resta y fijar un valor umbralo, bajo el cual diremos que es la misma persona y sobre el cual diremos que no lo es. Este método funciona, y si tenemos fotos muy bien tomadas, en alta resolución y buena iluminación si funciona. Pero es obviamente muy susceptible a errores cuando las condiciones no son las optimas (mala iluminación, baja resolución o mala calidad de la foto, la persona no está mirando de frente, uso de lentes, mascarilla, etc). En este proyecto usaremos un algoritmo basado en secuencias de rostros recortadas desde el video. El uso de una secuencia, en vez de solo un recorte, busca hacer mucho más robusto al algoritmo.
El código
El código esta disponible para su uso libre y gratuito en https://github.com/toopazo/airflow. Allí mismo están todas las instrucciones de instalación y ejecución.
El código hace uso de Docker para levantar una imagen de Postgres y una imagen de inferencia, ademas de otra para realizar el procesamiento de IA y el reconocimiento de rostros.
Resultados al dia 5 de Diciembre de 2024.
Actualmente el código lee el video y procesa cada frame. Extrae de él los rostros y los almacena en las siguientes tablas de la base de datos

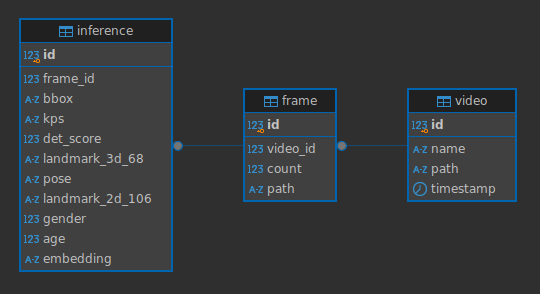
Luego el sistema consulta directamente a la base de datos para ejecutar los pasos:
- [Paso 1] Filtrado de los rostros: Se filtran los rostros detectados para solo utilizar aquellos que sean «reconocibles». Es decir, que la resolución sea suficiente, que miren de frente, etc.
- [Paso 2] Detección de secuencias: Cada rostro detectado forma parte de una secuencia de imágenes en donde la persona está en escena. Toda la secuencia se detecta y se le asigna una ID a manera de tracking de rostros. Este ID es utilizado para luego re-conocer cuando ese rostros vuelva a aparecer en escena.
- [Paso 3] Comparación de vectores: Acá se comparan secuencias de rostros actualmente visibles (ver ejemplo de la imagen de más abajo) contra todo lo almacenado en la base datos en búsqueda de coincidencias.
